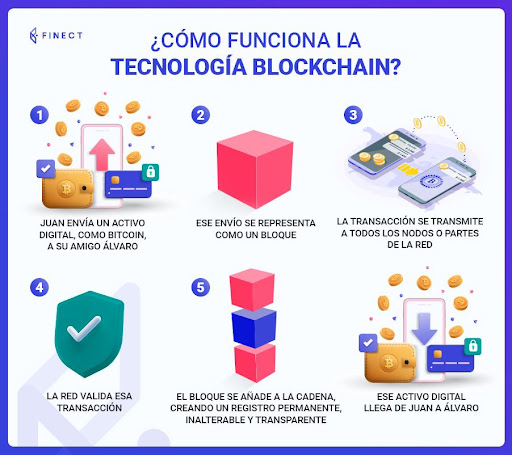
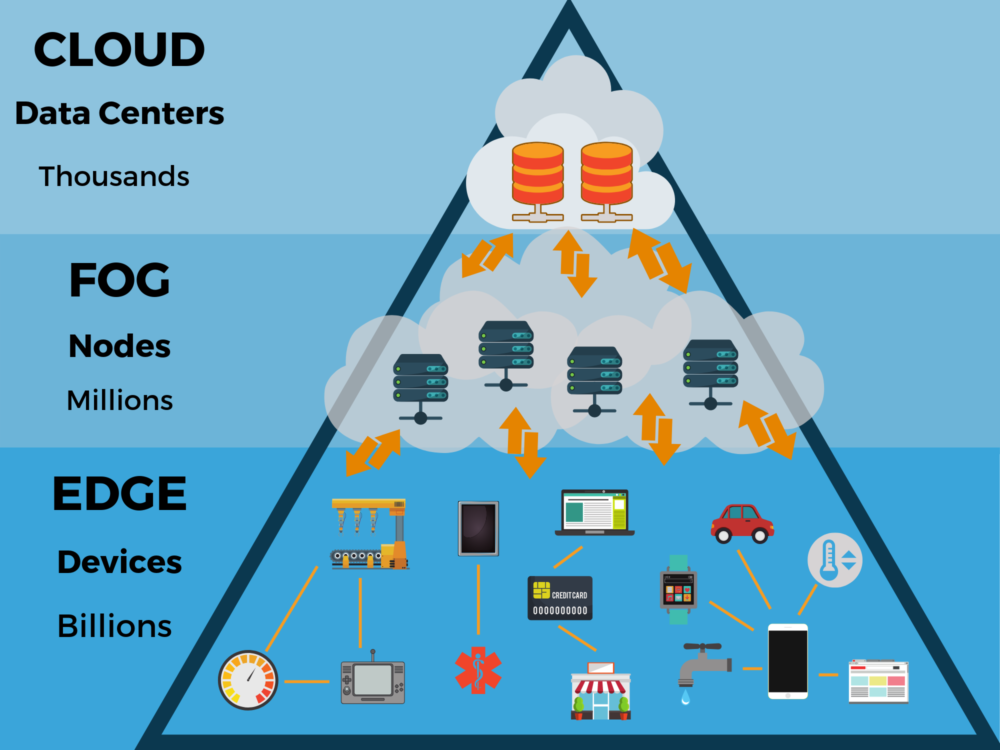
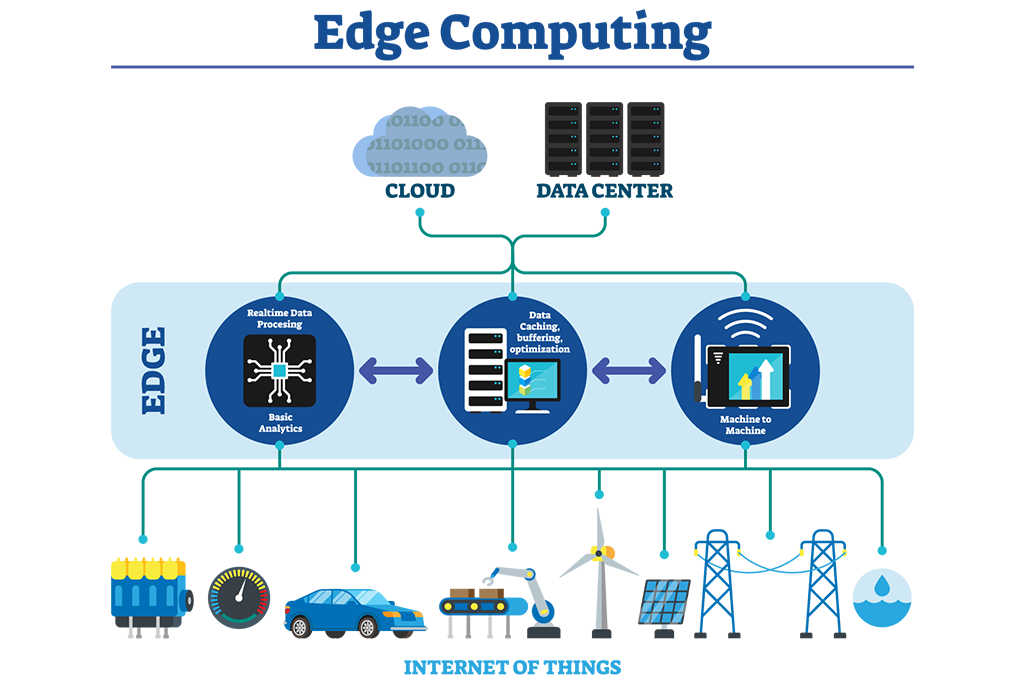
Si una empresa tiene un conocimiento profundo de sus procesos y tareas, y dispone de un sistema eficiente para capturar y analizar información, cuenta con los dos ingredientes fundamentales que le garantizan su crecimiento y éxito.
Vivimos en un entorno digital, donde internet, los teléfonos móviles y las nuevas tecnologías se emplean a diario por parte de personas, organizaciones, administraciones y empresas para realizar todo tipo de tareas. La cantidad de datos que se generan es inmensa y requiere del uso de herramientas y tecnologías adecuadas para su organización y análisis (como el big data o la inteligencia artificial, por ejemplo).
Una buena captación de datos permitirá que la empresa gestione de manera eficiente todos esos datos estructurados y no estructurados que maneja, obteniendo información útil con la que tomar mejores decisiones, lo que le permite aprovechar oportunidades y tendencias de mercado, y disponer de una ventaja competitiva sobre sus rivales.
¿Cuáles son las etapas de la captación de datos?
Para obtener datos estratégicos para una empresa mediante el análisis de grandes volúmenes de información procedente de diversas fuentes, es necesario pasar por distintas etapas de captura.
1 . Clasificación de las fuentes de datos
Las empresas generan y reciben datos de diversas fuentes de información, mucho más hoy en día con la existencia de nuevos canales como las redes sociales, el correo electrónico, los chats online, etc.
La primera etapa en la captación o captura de datos es realizar una correcta clasificación de todas esas fuentes de datos (para poder tratar la información según las necesidades del negocio).
2 . Extracción o captura de datos
La siguiente fase es establecer las herramientas y tecnologías a utilizar para extraer la información de cada una de esas fuentes de datos anteriormente clasificadas. Existen diferentes tecnologías aplicables para la captación de datos como OCR (reconocimiento óptico de caracteres), ICR (reconocimiento inteligente de caracteres, OMR (reconocimiento óptico de marcas), lectura de códigos QR, o IDR (reconocimiento inteligente de documentos), entre otros.
3 . Validación y exportación de la información
Es imprescindible que todos los datos que se capturen sean validados, es decir, corroborar que se trata del tipo de dato deseado y que se encuentran en el formato adecuado. En esta fase se verifica que la información gestionada esté alineada con el sistema de gestión documental utilizado.
Los datos una vez validados deben incorporarse a los sistemas de información que utilice la empresa (aplicaciones, herramientas, bases de datos…), para poder trabajar con ellos y garantizar su accesibilidad.
Aunque hemos empaquetado la validación y la exportación de datos en la misma fase, dependiendo del volumen y tipos de datos que se manejen, pueden tratarse como dos etapas diferenciadas.
Ventajas de la captación de datos
La captación de datos eficiente permite que la empresa cuente con una base de datos bien construida y desarrollada para toda la información que maneja el negocio (clientes, proveedores, productos…).
Veamos cuáles son los principales beneficios que ofrece implementar un buen sistema de captación de datos para una empresa.
Optimizar las inversiones y reducir el gasto
Con una buena captación de datos, las empresas disponen de información real que les permiten tomar mejores decisiones a la hora de invertir y ahorrar costes (en campañas de marketing digital, a la hora de realizar compras a proveedores, o al realizar inversiones, por ejemplo).
Detectar oportunidades de mercado
Los sistemas de captación y análisis de datos son fundamentales para que la empresa pueda detectar tendencias y nuevas oportunidades de mercado, y así reaccionar de forma inmediata para poder sacar beneficio de ellas.
Mejorar la satisfacción del cliente
Una buena base de datos de clientes con información valiosa sobre los mismos permite mejorar su experiencia de usuario y su grado de satisfacción, lo que aportará beneficios muy interesantes para la empresa como:
- Incremento de las ventas. Los clientes reciben productos y servicios que realmente se adaptan a sus expectativas y necesidades por lo que aumentarán las ventas del negocio.
- Aumento de la fidelidad. La información capturada y analizada permite optimizar los programas y campañas de fidelización de clientes.
- Captación de nuevos clientes. Los clientes satisfechos recomendarán la empresa en sus círculos cercanos (familia, amigos, compañeros de trabajo…).
Mejorar el funcionamiento de la empresa
Capturar y analizar información de manera eficiente permitirá que la empresa obtenga conocimiento útil para mejorar sus procesos y tareas. La captación de datos permite identificar aquellos procesos que no están siendo eficientes o no aportan valor al negocio, para poder mejorarlos o sustituirlos por otros más modernos y rentables.
Las empresas con un enfoque basado en datos (data driven) son mucho más productivas y consiguen elevar su nivel competitivo. Al estar basada en procesos automatizados, la captación de datos ayuda a acelerar los procesos empresariales y eliminar o minimizar los errores.
Mejora el rendimiento de los trabajadores
Una gestión eficiente de la información proporciona a los empleados de la empresa de los datos que necesitan para realizar sus labores de forma más rápida y eficiente, consiguiendo que sean más productivos y que se impliquen más con el negocio.
Hemos hablado sobre la gran importancia de la captación de datos para cualquier empresa hoy en día. Disponer de un sistema moderno y eficiente para capturar, organizar y analizar la información que maneja una empresa se hace imprescindible para que pueda alcanzar el éxito en un mercado actual tan competitivo donde los datos y las nuevas tecnologías son indispensables.